

How To Design Software Architecture For Startups
A good software architecture for a startup looks very different from the one you might build for an enterprise system. Here is what worked for us.

In the last few years I have worked with my brother on several private app projects and learned a lot about product and software development. A lot of things that we take for granted today posed big questions for us back then. On this blog we want to share our experiences and learnings with everyone who is interested or who is facing similar tasks.
In my non-free time, I work as a Senior Consultant and Software Architect for INNOQ.
There is a lot of information out there on how to build software for enterprise systems. If you are designing a system for a startup, a lot of these patterns and techniques simply don't work well. High levels of uncertainty, the need for maximum flexibility and a quick pace as well as serious restrictions in (wo-)manpower are challenges that are often unique to startups. On the other hand, startups can make compromises that enterprises can't make.
Deciding on a good backend architecture for our app, häpps, was one of the most challenging decisions we had to make. Even for experienced software architects, this decision is always a complicated one because it sets the stage for future development. The fact that we are a startup and therefore only two programmers with no extra capital complicates everything further. Also, making architecture decisions is an ongoing process, because young apps tend to evolve in unforeseen ways. It's essential to have a backend architecture that can quickly evolve and adapt to new requirements. Flexibility is a crucial requirement - it may even be the most important one. But what does it mean to build a flexible architecture for a startup?
Throughout my career, I have designed (or was involved in the design of) many backend architectures for both startups and enterprise systems. All of that experience went into the design and re-design of our own app backend. In this blog post, I'd like to share our discussions, arguments and insecurities, the resulting architecture, and the challenges and compromises we faced. I'll present the architecture that worked for us and what I would change if I had to do it all over again. However, please note that this article is not a definitive manual that is suitable for all apps. It is also quite opinionated, and the approaches presented may be debatable.
What does our app do?
Very simplified, the app allows the user to create so-called happenings. These are temporary groups organized not around a fixed set of people but around an occasion, something like a gathering or a party. Users can invite people to happenings and invited users can accept or decline invitations. Once a user accepts an invitation, they are part of that happening and can read and write in a chat and participate in further planning. Every happening also has a gif, video or image as its background media. On top of that, users have profiles and can befriend each other. A surprisingly complex part of the backend system is only concerned with push notifications. These notifications are sent on a great number of occasions: From friend requests to new chat messages, reactions, accepted invitations, time or place changes or as a reminder for open invitations and upcoming happenings.
The app as it is now has a fairly complex backend architecture spanning at least a dozen services and multiple means to share data and events between them. All of this was built mostly by one person and all of it runs smoothly. The overall level of complexity at the time of writing is much bigger than it was in the beginning. But mainly because of small features and improvements that required a lot of back-and-forth of information between services. The app's main features mentioned above are pretty much the ones we built from the very beginning.
Microservices usually don't work well for startups
When we started building häpps, the microservice hype was full on and deeply influenced our discussions. We quickly agreed that the term microservice is somewhat misleading because it seems to suggest cutting services as small as possible. Splitting your codebase into multiple independent services comes with a lot of disadvantages: Each service has to be maintained and deployed and increases the boilerplate needed for shared data structures, complicated communication protocols and infrastructure. By the time we released our app, the common library used by most services has been updated over a hundred times. And every service has to follow suit eventually.
And there is more: Most advantages of multi-service architectures for some enterprise-sized systems won't be relevant for a startup at all.
The most important one: The ability to deploy services independently doesn't matter for early startups. You don't have autonomous teams if you only have one or two teams. In this scenario, the individual deployment of multiple services is an impediment, not an advantage. The concern of the whole system crashing because one developer messed up on one end is also irrelevant as long as everyone works on all ends at once and you don't risk revenue losses because hundreds of users use your platform at the same time.
If you are lucky enough to reach a point where the horizontal scaling of a monolith isn't enough to keep your backend going, you will also be at a point where you have to rewrite big parts of your business logic and make performance improvements in data structures, database queries, caching and serialization. If you start with a relatively small user base, using up-to-date technology and frameworks, you should easily be able to scale your systems two or three orders of magnitude before you have to change your macro architecture.
So all of this sounds like a strong case against a multi-service architecture - and it is. But as you will see, we somewhat came around eventually. There are still reasons you might split up your backend. And there are better and worse ways to do it. If making services as small as possible in their distinct domain isn't the solution, then how do we determine reasonable boundaries?
Move fast and outsource things
There are a lot of components in your app backend that – although crucial – don’t relate to the core domain of your app. These are also the services that you shouldn’t build yourself:
Auth services, obviously
A push notification or cloud message distributor
Media services that store uploaded images and take care of things like downsizing, cropping, scaling and caching
A chat server (?)
One of my favorite decisions on this project was to use Google Firebase. We knew we didn’t want to use it for data storage or computation (and we’re glad we did not!). But we implemented Firebase Auth so we could use their simple kits to take care of everything auth-related, including social logins and password resets. These are the kind of things that you, as an app developer that has to deliver features, can’t afford to spend more time on than necessary to ensure safety.
We also used Google Firebase Cloud Messaging to have a single interface that delivers push notifications to both Android and IOS devices. This decision served us well for a while but Google's lack of flexibility to cover the ever-growing complexity of our push notifications made us doubt the decision. We might have been better off with a system like OneSignal.
We ended up using a self-developed service to take care of our uploaded media for the only reason that we had it sitting around from an old project with similar requirements. If you don’t already have one, I would recommend using a CDN or some kind of ready-deployable open-source container to do the job. Media management gets quite complicated quite fast when you try to keep your user's data usage within reasonable boundaries.
The chat server is somewhat of an unclear case. While building a chat is a rather complex problem, it is also one that has also been solved hundreds of times before. We had lengthy discussions about whether we should implement a ready chat server solution or build our own on top of a more low-level WebSocket framework. We eventually decided to do the latter and I am glad we did. All in all, it turned out that the actual chatting part of the chat server was easier to implement than we thought (that’s only true for the backend!). On the other hand, the chat turned out to be tightly coupled with many of the other app's core features, so it would have become more and more difficult to build on a generic product.
While we're at it, let's talk about reusable components for backend systems.
Consider building reusable things
To think about reusability on a level that goes beyond one app might seem a little over the top - but I promise you, it's not. You might be convinced that what you build now will be a hit, but the more likely scenario is that you fail, learn from it and end up building something again. But even if that's not the case - if the product you're building will be a success, building somewhat reusable things will increase your ability to adapt to whatever user feedback you get for your MVP.
By the time we started to build our second app, it was obvious that we wanted to move as fast as possible to be able to validate our ideas. We decided to use familiar technologies and a simpler architecture. We also looked at old projects to find reusable code. Our media service - a simple python app that handled image uploads and served static media - was one component that could be reused with minor modifications.
We knew that this time might not be the last time we decide to build a product - whether it would be a success or not. So we decided to try to build reusable services and components.
Not every service can or should be built with reusability in mind. One of the mistakes I witness the most is a tendency to build something generic for something that is very specific: Your domain logic. The result of this is an overly complicated, boilerplate code base that slows down your product development. Thinking about this will also push you in the right direction. Which part of the system does represent the core business logic of your product and which doesn't? The backbone of your chat server? It shouldn't have any special knowledge about your app. The user profile service? Doesn't care what kind of profiles it manages. The push notification gateway? It only manages device tokens and forwards notifications to Firebase. The async message hub? Its job is to register clients and deliver arbitrary JSON messages. All of these systems can be built in a reusable manner. They should be! That doesn't necessarily mean they all have to be standalone services connected by HTTP APIs. If you commit to a programming language and a web framework, you might as well build them as modules and keep them isolated well enough to be able to separate them from your monolith at any time in the future.
There should be no pressure to make everything as reusable as possible. After all, your goal is still to deliver quickly and in the end, it's not certain if you'll ever have another use case for these systems. But thinking about reusability also forces you to think about your whole backend system in terms of domain logic and isolation, something that will pay off later on.
Be pragmatic
Because not everything that works on paper is fun to implement in practice. We ended up splitting some systems and joining others based on compromises and pure pragmatism.
Our friendship service is one example of this. The app enables users to add others as friends. So in its essence, the corresponding service only manages relations between user ids. In theory, it could be used for all kinds of apps, so in the beginning, it was a separate service. But we soon realized that it was tightly coupled to the user profile service: Often, if a list of user profiles is returned to a client, each profile in the list should include a flag indicating if that user is a friend of the user requesting the list. On the other hand, when a list of friends is returned from the friendship service, it should often include profile information such as the users' names. We eventually ended up joining these services into one, but keep their logic in separate modules.
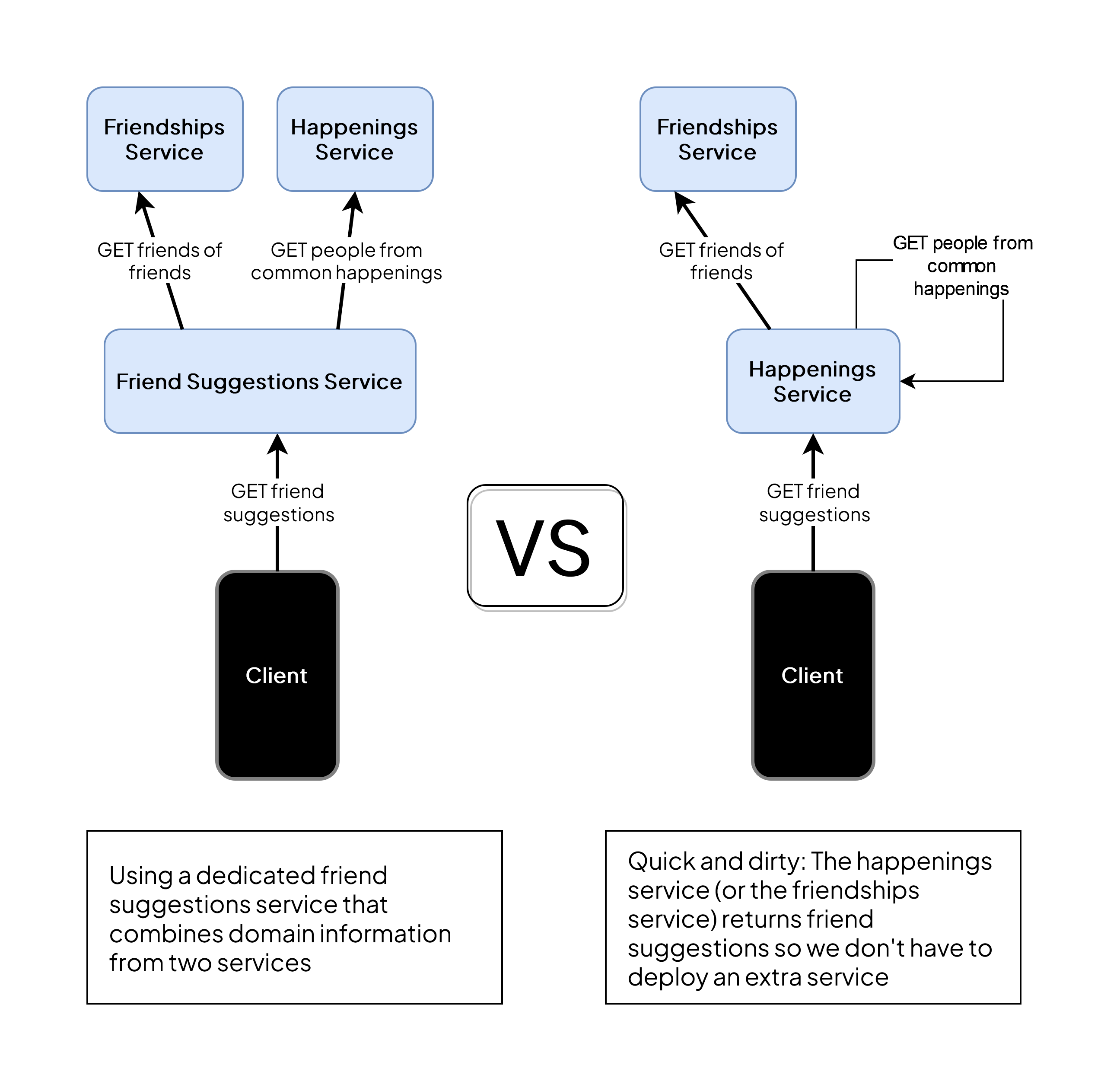
It's easy to lose yourself in thought loops about isolated systems. Consider an API that should return a list of friend suggestions. These suggestions might include friends of friends - information that's stored in the friendships service. But in a second iteration, you may also want to suggest people who attended the same happening as the user. This information comes from a completely different system and it would be easy to argue, the friendship suggestions should actually be a microservice of its own since it combines data from different domains. Then again, the minimal amount of business logic required to join lists of user profiles to a single list of suggestions doesn't justify the maintenance and deployment of a service of its own. In a situation like this, it might instead just be time to look the other way and implement some domain awareness between otherwise independent systems. It's not pretty but it works: Have one of your existing services return the user's friendship suggestions, even if it's not a perfect fit. In our case, we decided to let the happenings service do the job, to keep the friendships service clean of code that belongs to another domain. You might as well choose to do it the other way around or build a kind of miscellaneous service that works as a collection of smaller services.
Boundaries along sync/async communication patterns
Another reason to split your system into services relates to scalability - kind of. Consider a complex action that triggers a lot of complicated, asynchronous side effects.
Take for example a user who decides to join a happening. On the happening service level, a new relation between the user and the happening will be created before the backend sends an asynchronous update prompt to all registered clients, asking them to reload the updated happening from the server. This is a fast, synchronous request. But this action triggers a lot of other side-effects: A system message will be sent to the chat backend so that an info message is displayed in the chat - but only if that feature is activated. Personalized push notifications will be sent to an unknown number of friends and other relevant happening members. That in turn requires querying the database for other relations between happenings and users, existing friendships, user profiles and notification settings. The system will also have to update the notification badge count on the IOS devices of everyone who can see the happening. Determining the correct badge count, however, requires recounting or gathering the overall number of unread chat messages and several other pieces of information.
Performing multiple tasks synchronously can result in long request times, ultimately leading to failed requests. Additionally, the number of side effects generated by these tasks tends to increase at a faster rate than the number of core features. Even if you wrote every line of code in your project yourself, it can be challenging to determine how many other actions are triggered by complex actions.
In the bigger picture, decoupling these things is usually a smart decision. Splitting a system along these boundaries e.g. by using a message broker like rabbitMQ or Kafka can have advantages in terms of scalability later on. However, in the early stages of product development, it's often sufficient to just stick to one app and make use of internal event emitters.
How we did it and how we would do it next time
We ultimately divided our backend system into multiple services, based on all the considerations discussed above. Secondary services for authentication, push notifications, media management and monitoring were a no-brainer.
We also decided to separate systems along communication patterns and reusability considerations. However, we soon learned a lesson in pragmatism: Systems that talk a lot to each other - and only synchronously - should not be separated at first, even if their domains suggest it. Instead, strict modularization will take you a long way.
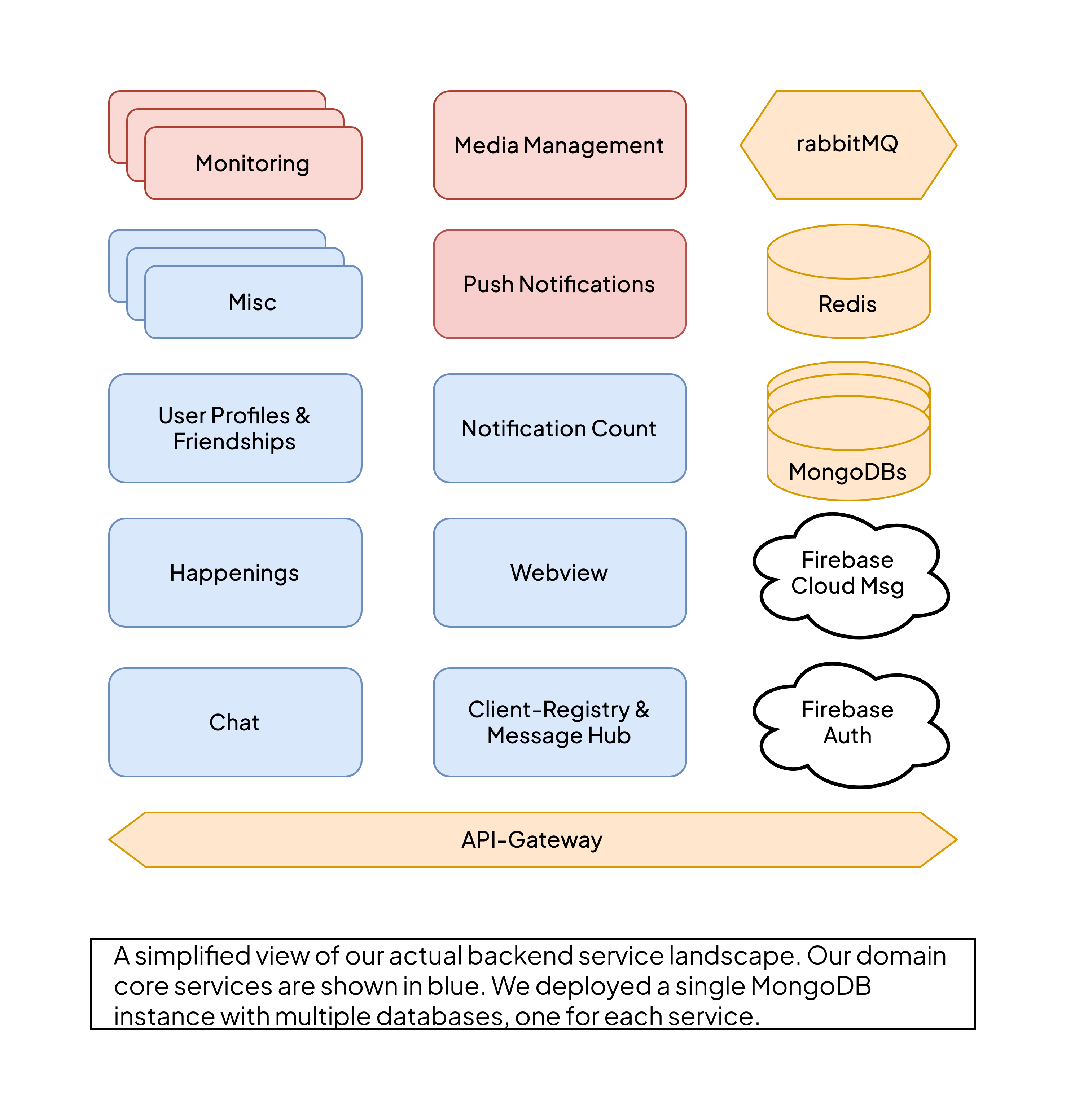
We are still incredibly pleased with the architecture we selected. It runs smoothly and scales effortlessly, particularly when we add new features. Even though it involves multiple domain services communicating with each other, we've encountered almost no issues related to inter-service communication. This is largely thanks to our comprehensive end-to-end test coverage and our straightforward yet robust communication patterns between services.
But this also required a lot of work: We spent a fair amount of time developing a common library that did not contain any domain logic but all the interfaces and data structures required for the communication between services. This again, was a compromise in favor of keeping things easy.
Developing robust inter-service communication protocols that are suitable for a startup takes time as well. All of this was good work that we would have to do sooner or later if our app would have been a smashing success - which it wasn't. And that's kind of the takeaway.
That's why, if we would have to do it all over again, I would choose a slightly different approach. In the spirit of moving faster towards a minimum viable product, there is still room to cut back on fancy architecture patterns and built a simpler backend architecture - you guessed it - our old friend, the monolith.
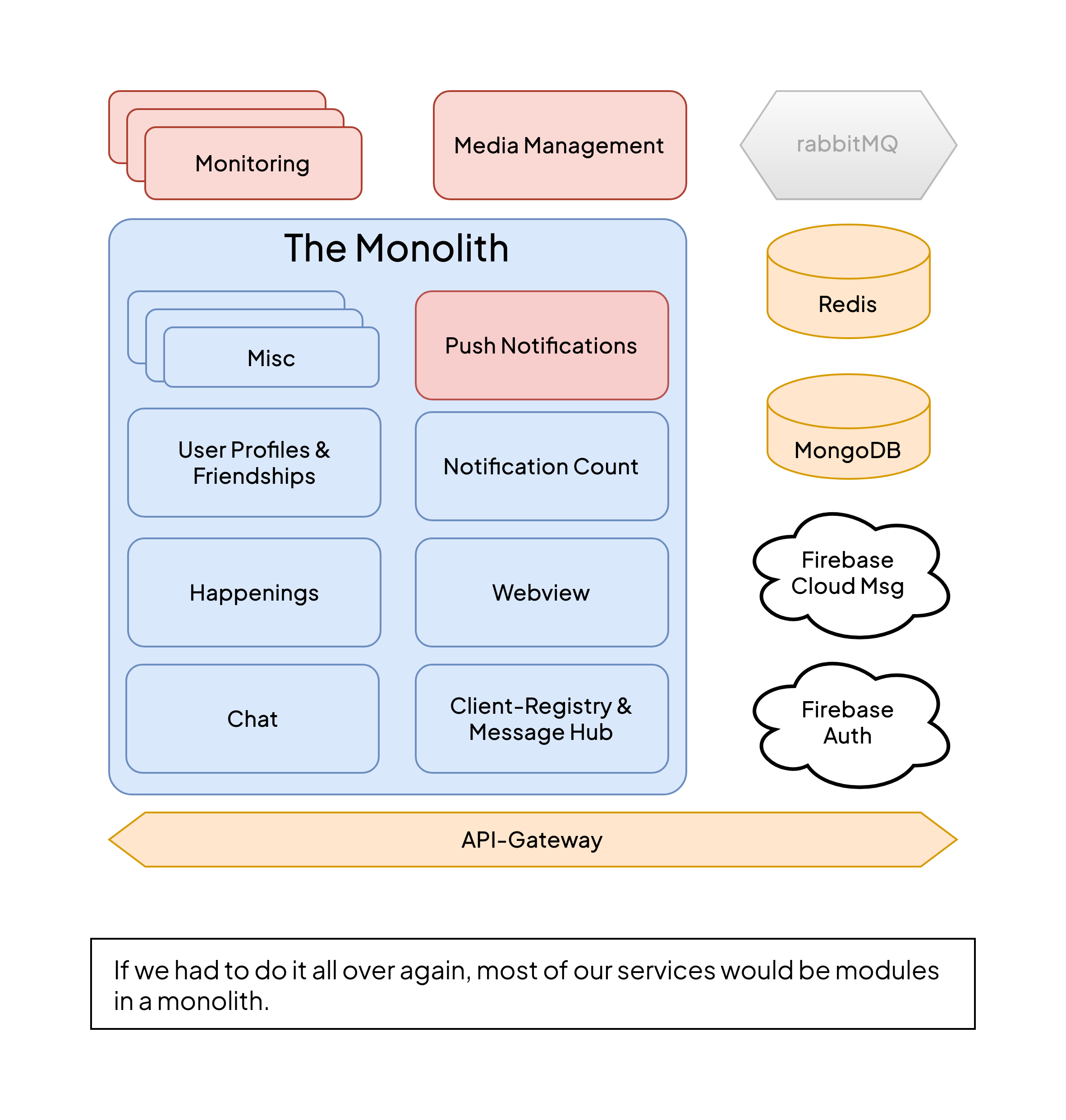
During the process of building and deploying a multi-service landscape, we learned a lot about software architecture. We gained valuable insights on how to cut, develop and maintain a multi-service landscape with minimum effort. We also learned a lot from the inter-service communication patterns we designed. However, if your objective is not to learn about the architecture of distributed systems but to efficiently ship a product, it makes sense to opt for a more monolithic approach. If we were to start over, I would choose to build a single system that consists of well-isolated modules with unassuming APIs between them. In place of a separate message broker like rabbitMQ, I would opt for a local event emitter, at least at first. This approach would have saved us a significant amount of time that we could have spent on new features - or for something that we have criminally neglected - marketing.
About flexibility
The most valuable lesson that we learned over the years is that you have to move fast. This applies especially to the early stages of product development. You will almost certainly be wrong about how exactly your product and its features will be received by users. Few ideas will actually end up being successful, at least at first. In that sense, having a high degree of flexibility also means: Whatever you build should be cheap enough to be thrown overboard in case it's not adapted by users, but solid enough so it can be easily improved and built upon in case it is a success. The goal is to spend as little time as possible working on unverified features so that you have as much time as possible to follow up on the ones that your users love.



