

Simplifying Service-to-Service Communication
After our team struggled to keep up with our distributed systems architecture, here is how we reduced complexity in inter-service communication.

In the last few years I have worked with my brother on several private app projects and learned a lot about product and software development. A lot of things that we take for granted today posed big questions for us back then. On this blog we want to share our experiences and learnings with everyone who is interested or who is facing similar tasks.
In my non-free time, I work as a Senior Consultant and Software Architect for INNOQ.
Although there are good reasons for some software projects to implement a distributed systems architecture, these reasons rarely apply to smaller projects or startups. Often teams end up in a situation where the complexity that comes with these types of architectures outweighs their advantages to the point that progress can only be made in small steps. Distributed systems bring complexity that usually comes with a lot of additional mental load for developers. From every extra boundary layer between systems, distributed state management and integration tests to inter-service communication protocols - at some point, we move beyond the sweet spot for complexity.
This can happen for a variety of reasons. Maybe you just underestimated the compounding complexity or maybe someone took good principles too far. A very common scenario is that growth expectations weren't met or that the company has not managed to hire enough new developers to match the number of systems.
An obvious approach would be to merge some systems back together. However, this is sometimes not useful or possible for various reasons, e.g. because different tech stacks were used.
For our startup, complex communication patterns that should ensure reliable communication between the services represent the greatest overhead. So we looked for compromises that would allow us to simplify this part of our architecture.
These solutions worked for us because as a startup, we can make certain compromises without risking major disadvantages. The kind of compromises your team can make may be different. In any case, it is important to understand the challenges we try to solve, the risks that arise from poor design decisions and the advantages and disadvantages of different compromises to be able to simplify a system. Nothing is for free.
I’ll start out discussing challenges and risks in inter-service communications, and how we usually tackle them in enterprise-level architectures. I will explain why these approaches may not suit your startup and what compromises can be made to move faster and build a system that is easier to understand and maintain.
Why should we replicate state?
There are multiple reasons to have well-isolated systems in enterprise architecture. One major advantage is that it enables multiple teams to develop and ship major parts of your system individually - at least in theory. Another good reason for a high degree of isolation is that your services can run independently. So if one service gets stuck, your clients will still be able to use the rest of your application - also at least in theory.
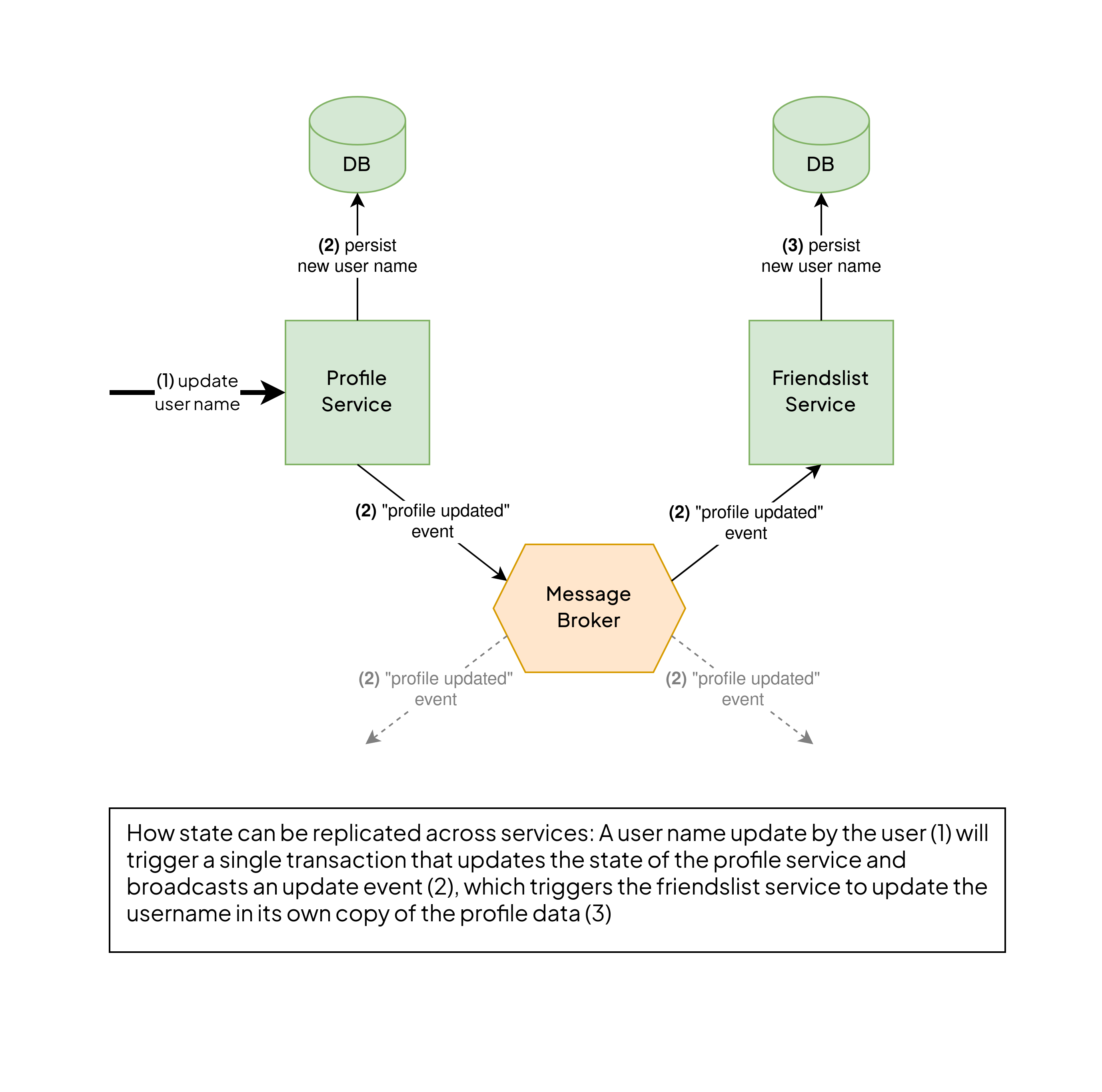
To reach that high degree of isolation, each system must own all the data it needs to operate properly. That’s because, if your user profiles service goes down, for your, say, friendslist service to still be operational, it needs its own copy of the necessary information, for example, a relation between user ids and user names.
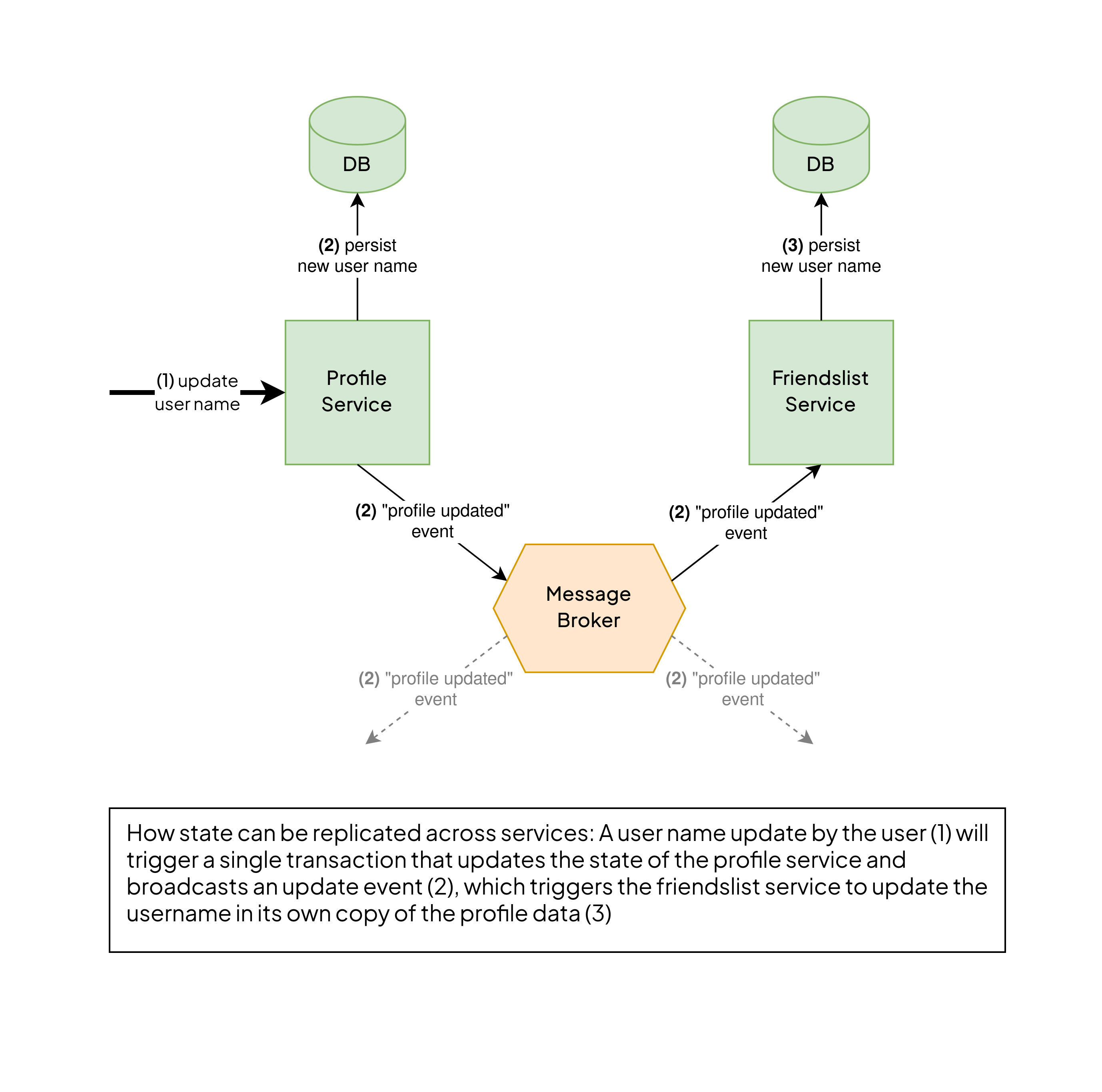
That often means that your friendslist service has its own database and state updates have to reliably be propagated from the users service to the friendslist service. So, for example, if a user changes their name, you want the friendslist service to take notice and update its copy of the relevant information.
How we replicate state, the enterprise approach
There are multiple strategies out there to achieve this in the enterprise world. Oftentimes, architects choose some form of asynchronous event stream. So if a user updates their profile, a “profile-updated”-event containing the information is broadcasted and every service interested in this kind of information can consume these events and update the needed information in their own database.
This is often achieved using some kind of event feed. Meaning that all published events are stored sequentially so that they can be replayed at any time. This means that if you were to deploy a new service or, for some reason, wipe the database of an existing one, it would be able to replay all the “user-profile-updated”-events and end up with an up-to-date copy of the needed information. Two technologies often used for that kind of approach are HTTP Feeds and Apache Kafka.
Where it gets complicated
The problem with asynchronous, event-driven communication is that you have to ensure that state updates are actually propagated across systems. That means: Every state change usually involves two technologies, the database of your choice to persist the state and some kind of message dispatcher to publish the state update event for other systems to consume. The trick is to make sure that one action only happens if the other one is successful. We usually don't want to propagate a state change that wasn't persisted properly. But we also don't want to persist a change that wasn't announced to other systems.
This means we need to design transactional behavior that includes more than one technology.
Even if it’s ensured that your state update event will only be published if your database state was updated successfully (and vice versa), it’s still uncertain if that event successfully reached all supposed subscribing services and updated their states accordingly. What happens, if the transactional state update of the dependent service fails after it receives a state-update event?
As you can see, this stuff gets pretty nasty pretty quickly.
If something goes wrong, you might end up with contradictory states and no easy way to resolve them. You may not even notice the problem until chaotic behavior causes problems in far-away and seemingly unrelated places and processes.
Common approaches that try to resolve these problems include the Transactional Outbox Pattern or Event Sourcing. We won’t use any of them.
If communication goes wrong, the consequences could be dear
I remember that a few months ago, a big fashion retailer rolled out a new payment process that enabled customers to try on their items and then pay individually for the ones kept in the order overview. It was a pretty convenient feature, so I used it to pay for all my items and - as expected - all payments were listed as complete in my account.
Several weeks after placing my orders, my inbox was filled with notifications of overdue payments. Initially, I disregarded the emails, assuming it was just another delay in the system, as I had experienced this before. But then, I received another barrage of emails, now accompanied by threats of account suspension and even the possibility of legal action if I failed to make the payments promptly.
It seems like whatever system was responsible for sending out those reminders was not aware that my payments were completed.
Not only was that situation incredibly annoying for me as a customer, it also made me occupy their service hotlines for quite some time.
Imagine how messy something like this could be in the aftermath if it happens in your system. Not only do you have to find the bug. Your team may have to look for missing or existing payments and roll back whatever chain of events the overdue notice might have triggered. Some accounts might have already been unjustly suspended, cutting your revenue and, if it’s really bad, your legal team might already have taken things further against some of your loyal customers.
If your system misses a like on a post or doesn’t send out a push notification due to a swallowed event or an inconsistent state, it usually doesn’t really matter. Especially as a startup with a young app, you are on the frontline for other problems. But this example shows that, depending on what your app does, things can go bad really quickly if you lack a solid concept for inter-service communication.
Therefore, it is essential to ensure that, regardless of any compromises made to our architecture, these issues should never occur, or if they do, their impact should be neglectable.
Why small teams need a different approach
All these approaches come at higher, hidden costs. Maintaining copies of data in multiple sources will not only occupy a good part of your mental capacity for every future architecture and code change, but it also increases your cost and need for infrastructure maintenance.
As a software architect or engineer in a small team or a startup, your primary responsibility is usually to make progress. And that means you have to ship features and be able to quickly make changes to whatever you built. This requires making compromises, and the key challenge is to make these compromises in a manner that enables you to build upon them and sustain that progress.
If your team is small, there are really two ways to optimize your work. Firstly, you have to take some shortcuts to accelerate communication and implementation. Secondly, it's crucial to minimize the amount of future work that you create for yourselves. That means you have to minimize maintenance.
Your cost of maintenance rises with every layer of abstraction, with every test and with every deployed service. That doesn’t mean all those things are bad. But with seriously limited resources, we have to question which of those things are actually necessary and useful.
Let’s make some compromises
As we’ve seen, things are complicated. We don’t want to make any compromises that can cause state inconsistencies across our service landscape. But it seems there is no way around using complicated transaction and rollback patterns if we want to ensure consistency.
Since we would also like to avoid maintaining a large number of data sources, the solution here seems obvious: Dropping the idea that each system owns its own, independent state seems to resolve a lot of our problems. This would mean, you store your data in a single place, the single source of truth, namely the system that is responsible for it.
So, to tie it to the previous example: Only the payment system has information about which items are paid. Other systems won’t hold a copy of the payment information but will instead query the real state once they need it, for example, to figure out who will receive a payment reminder and who won’t
Back to a single-state solution
But wait, wasn’t there a good reason for each system to hold its own data?
For once, you pay with tighter coupling between the systems. Once the payments system is down, all other systems that need some information from it won’t be able to operate properly either. This is a problem for big enterprise systems with hundreds or thousands of concurrent users and customers but it's not a problem for our startup, at least not for a long while. Once it becomes a problem, the architecture can be improved.
Another problem is that you put a somewhat unpredictable load on your root system.
Let’s say one of your core services manages user profiles and is the single source of truth for user names. Because user names are needed in many other services, a single page load that queries several services can cause a lot of subsequent requests to the user profiles service. How many exactly is often hard to say as your architecture grows. But even if your app serves a few hundred concurrent users (and that’s quite optimistic in the beginning), these requests are easily manageable. Moreover, if both services run on the same machine or data center, HTTP requests are cheap and can be cached in the system holding the state of truth, if it becomes necessary.
The case for a message broker
Parts of your systems may still require a message broker to instantly publish events to other systems. Let’s say your app has a chatroom, a chat service that receives and stores messages and a push notification service that sends out any kind of push notifications to users' devices, not only the ones related to chat messages.
As soon as a user sends a new message, a push notification should instantly be sent to other users in the chatroom.
Implementing a periodic query for new messages from the chat service by the push notification service not only introduces a delay in triggering notifications but also creates an inverted service dependency. This requires the push notification service to know about the chat service and its API.
If the chat service were to make an HTTP post request to the push notification service, the direction of your service dependency is correct, but the chat service must be aware of all other services that might need to know about new chat messages.
A message broker solves all of these problems by decoupling services. The chat service publishes a “new message” event to a queue or topic, unaware of who might consume it. The push notification service consumes all messages with a certain routing prefix, unaware of their actual origin.
Because your message broker usually takes care of message routing and acknowledges received messages, this approach also scales well if you decide to deploy several instances of either service.
Does that mean we’re back to transactional updates? Not if we only use dispatched events to trigger actions, not to update data that belongs to another system. We would first store the new chat message in the chat service’s database and afterward publish a “new message” event to our message broker. In the unlikely case that that message gets lost, the worst that should happen is that the user doesn’t get a push notification.
It’s not perfect but it doesn’t cause problematic long-term consequences. As soon as the user reloads the chat history, the message will appear.
Now consider a third system that counts the number of notifications for the user. The overall number of notifications will be the sum of unread chat messages and other notifications. The effective way to make this work is to count and persist the number of “new message” events, add it to the count of other new notifications and publish the result. This is error-prone because a lost event can result in an incorrect count of unread messages indefinitely. To address this issue, the system should be designed to respond to the "new message" event by directly querying the chat service for the number of unread messages. This way, if any error occurs, it can be corrected with the next incoming event.
So far, these approaches and compromises resulted in an architecture that was easy to understand and resistant to state inconsistencies. It’s also relatively easy to maintain and works reliably in real-world app backends.
Some notes on our implementation
In our own app backend, we used the following approaches to implement the communication pattern.
Our synchronous inter-system communication was implemented using plain HTTP requests due to low dependency requirements and our familiarity with the technology.
Asynchronous real-time messages were distributed using rabbitMQ. The use of rabbitMQ was a suitable option, but there are other alternatives available.
We used a single MongoDB instance for data storage, with each service having its own separate database to ensure that no service directly queries another service's database.
To enhance consistency and ease of use, we implemented a common library for clients written in TypeScript. This library provides a typed interface for all internal HTTP request endpoints and message broker communications.
So far, none of the technology choices caused any problems. Would I have to implement this again, I would do it in the same way, using the same technologies. We chose the technologies above because we know them well. Different teams might be better off with different technologies.
What worked for us
These are the simplified principles that worked well for us:
Don’t replicate state across different systems: It comes with too much overhead and complexity while not providing any benefits for small teams and processes
Use HTTP requests to synchronously query data from other systems if it’s required
Use a message broker to send asynchronous real-time information across systems.
Use asynchronous events in fire-and-forget scenarios or to trigger a system to pull a state update from another system. Never use them to directly update another system’s state.
The compromise allowed us to maintain a compact codebase, minimize maintenance, and ensure consistency in states while ensuring real-time information flow across our systems. Although it may result in reduced performance and increased inter-system coupling, these trade-offs can be easily accepted for small teams with a limited user base in the early stages of product development.
Photo by Omar Flores on Unsplash



